LLMs
Visual Analogies
ARC
Human-Like Reasoning
Visual Analogies in Large Language Models vs. Humans
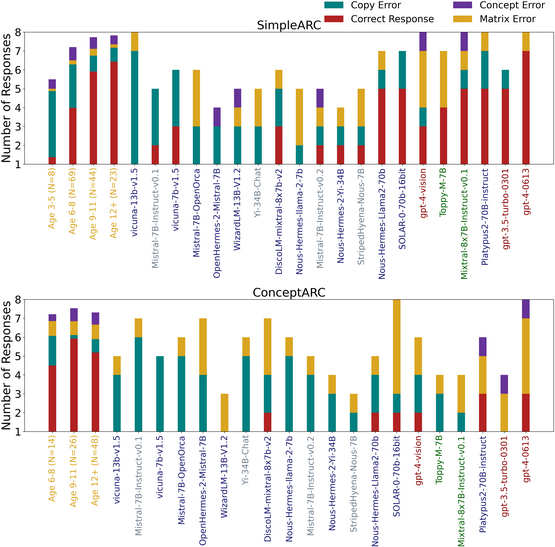
How well can Large Language Models (LLMs) solve visual analogy tests compared to humans? The study titled Do Large Language Models Solve ARC Visual Analogies Like People Do? explores this by comparing the performance of LLMs and people, particularly children, using the Abstraction Reasoning Corpus (ARC).
Key Points:
- Human vs. Machine: Children and adults generally perform better than most LLMs on ARC visual analogy tasks.
- Fascinating Strategies: Both LLMs and young children seem to rely on ‘fallback’ strategies—partially copying the analogy—for solutions.
- Error Analysis: LLMs and humans exhibit distinct error patterns, with LLMs more prone to combining analogy matrices and humans to conceptual errors.
- LLM Reasoning Insights: The paper offers a closer look at how LLMs approach visual analogies and what that reveals about their reasoning mechanisms.
The Significance: Understanding the difference between machine and human cognition is essential for AI research. This comparison not only delineates where LLMs currently stand but also indicates pathways for refining their reasoning capabilities to be more akin to human cognition. A pivotal read for those interested in cognitive AI and human-imitative reasoning approaches.
Personalized AI news from scientific papers.