AI Coaching
Vision Encoder
Text Decoder
Human-AI Interaction
Visual Recognition
Vision Encoder-Decoder Models for AI Coaching
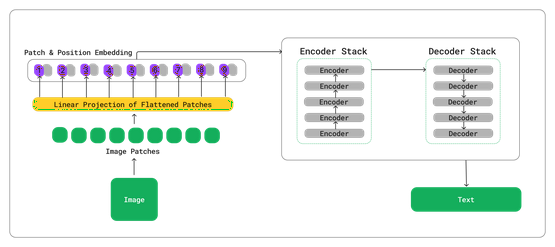
The integration of vision-encoder-decoder models represents a new paradigm in AI coaching, combining image recognition with textual interaction seamlessly. Key components of the model include:
- Vision Transformer as encoder: Handles visual inputs efficiently, providing a robust basis for feature extraction.
- GPT-2 as decoder: Enables natural language processing, facilitating intuitive AI-human interactions.
Applications and implications:
- Versatile use in various domains needing visual input
- Enhancements in human-AI interaction, making it more natural and intuitive
This paper explores the efficiency and potential of combining advanced visual and textual processing models to improve AI coaching systems, suggesting a broad range of applications from education to customer service. The approach could lead to more sophisticated, user-friendly AI systems that better understand and interact with human users.
Personalized AI news from scientific papers.