Multimodal Learning
Transformers
Data Integration
AI Training
Cross-modality Interaction
Training Transitive and Commutative Multimodal Transformers with LoReTTa
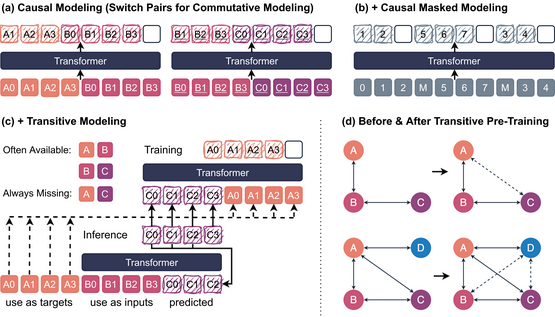
LoReTTa stands for Linking modalities with a Transitive and commutative pre-Training strategy, aimed at improving the integration of multiple data modalities (like text, image, and audio) in one model. This approach is particularly valuable in sectors where multimodality is essential but challenging due to data fragmentation. Key highlights include:
- In-depth exploration of the challenges in training multimodal systems.
- Implementation of rules of commutativity and transitivity in model training.
- Extensive testing across various domains, demonstrating improved performance over competitors.
- Insight into the potential for these models in handling complex data interaction scenarios. The promise of LoReTTa could revolutionize how we think about AI model training across different sectors, particularly those relying on rich, diverse data sets. It’s a step forward in creating more versatile and competent AI systems capable of interpreting and acting upon a wide range of data inputs.
Personalized AI news from scientific papers.