LLMs
Reinforcement Learning
Multi-Turn RL
Hierarchical RL
Agent Tasks
Training LLM Agents with Hierarchical RL
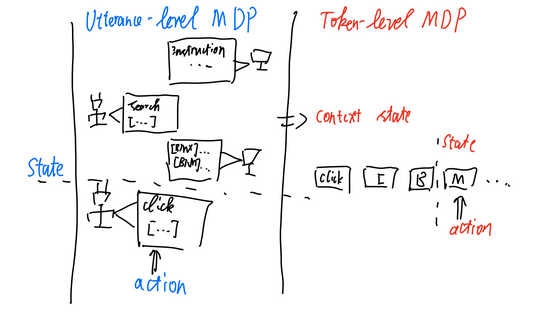
A revolutionary framework, ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL, presents a novel approach to training LLMs for agent tasks. Here are the key takeaways and our unique insights:
- Hierarchical reinforcement learning (RL) helps LLMs make intelligent decisions over multi-turn interactions, which is vital for tasks like web interaction or customer support.
- The framework includes a high-level off-policy value-based RL algorithm to accumulate rewards and a low-level RL algorithm for training a token policy within turns.
- Empirical results demonstrate that ArCHer significantly boosts efficiency and performance on agent tasks.
- The method attains 100x sample efficiency over existing methods and scales positively with larger model capacities.
In my opinion, this paper is pivotal as it addresses the challenge of multi-turn decision-making in LLMs with a scalable solution. The potential for further research in complex, real-world tasks like negotiation or strategizing is immense, paving the way for more autonomous and intelligent AI agents.
Personalized AI news from scientific papers.