Medical Imaging
Swin-UMamba
Image Segmentation
Vision Transformers
Convolutional Neural Networks
Swin-UMamba: A Leap in Medical Image Segmentation
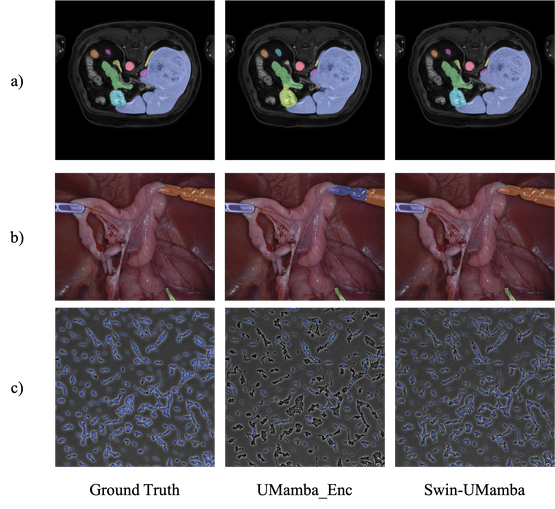
Accurate medical image segmentation is crucial for diagnosis and treatment, yet modeling long-range global information remains challenging. Conventional CNNs are limited by their localized receptive fields, and Vision Transformers face high computational complexity. The Swin-UMamba model innovates by integrating Mamba-based models with ImageNet pretraining for exceptional performance in medical image segmentation.
- Superior Segmentation: Swin-UMamba significantly outperforms established CNNs and ViTs.
- Impressive Efficiency: Lower memory usage and computational requirements.
- Cross-Domain Applicability: Performs excellently on diverse datasets such as AbdomenMRI and Microscopy.
- Open Source: The Swin-UMamba models and code are publicly available for the community.
This novel approach underlines the importance of leveraging pretraining to raise the bar in data-efficient medical image analysis. Swin-UMamba’s impressive results illustrate the potential for similar models to revolutionize other high-complexity imaging tasks.
Personalized AI news from scientific papers.