3D Face Reconstruction
Facial Expressions
Neural Rendering
SMIRK
SMIRK: Advanced 3D Facial Expression Reconstruction
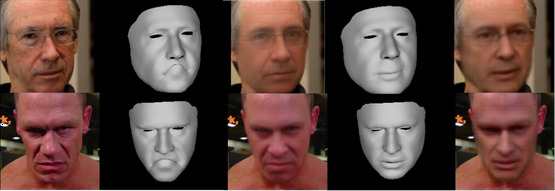
SMIRK (Spatial Modeling for Image-based Reconstruction of Kinesics) significantly enhances 3D face reconstruction, especially for capturing expressions. Limitations in self-supervised training and lack of expression diversity in training data were identified and addressed by SMIRK. By integrating a neural rendering module for image-based supervision focused on face geometry, SMIRK improves the reconstruction of diverse expressions. The approach augments training data with varying expressions, leading to improved expression reconstruction as evidenced in qualitative and quantitative assessments. For further details, view the project here.
- Focuses on improved reconstruction of 3D facial expressions
- Utilizes neural rendering to bridge the domain gap in training
- Allows augmentation of training data with varied expressions
- Demonstrates new state-of-the-art in accurate expression reconstruction
The key significance of this paper is the leap forward in 3D face reconstruction fidelity, particularly in regards to expressions that are rarely observed or challenging to capture. This development could benefit various applications from facial recognition security systems to digital entertainment industries where expressive avatars are necessary.
Personalized AI news from scientific papers.