LLM Agents
Security
Prompt Injection
Benchmarking
AI Safety
Securing LLM Agents Against Prompt Injection Attacks
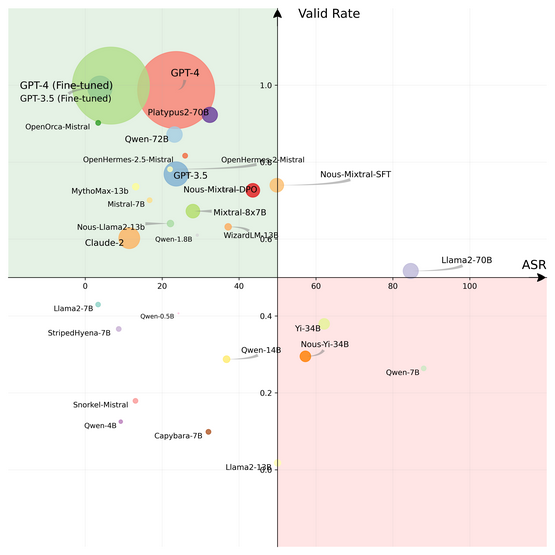
In a world where LLMs operate as agents interacting with tools and content, security becomes a paramount concern. Researchers Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang present ‘InjecAgent’ - a benchmark designed to evaluate LLM agent vulnerabilities to Indirect Prompt Injection (IPI) attacks.
- Introduces 1,054 test cases for analyzing vulnerabilities.
- Covers 17 user tools and 62 attacker tools.
- Categorizes attacks into user harm and private data exfiltration.
- Shows GPT-4 susceptibility to attacks in test scenarios.
The research highlights the necessity for rigorous security measures in the deployment of LLM agents. The profound implications of this study suggest that as AI systems become more integrated into daily workflows, it is imperative that their safety protocols evolve in tandem. This research marks a step towards understanding and mitigating the risks associated with enhanced AI capabilities.
Personalized AI news from scientific papers.