RLRF
LLM Improvement
Reflective Feedback
Model Alignment
RLRF Framework for Alignment and Improvement of LLMs
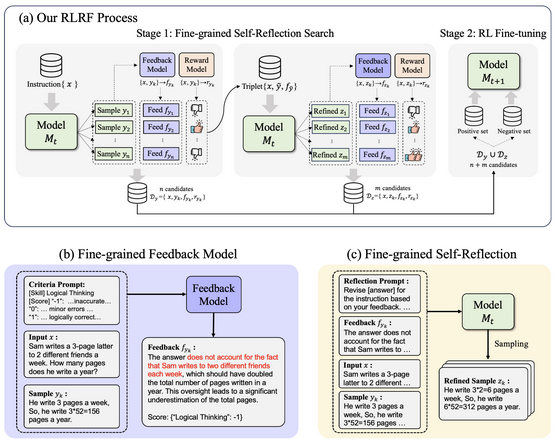
The Reinforcement Learning from Reflective Feedback (RLRF) framework offers a novel method for aligning large language models with human preferences while simultaneously improving their core capabilities.
Insights on RLRF:
- Employs a systematic self-reflection mechanism coupled with fine-tuning through RL algorithms.
- Prioritizes fine-grained feedback for robust enhancement of LLM responses.
- Demonstrates transformative potential for achieving deeper model alignment beyond surface-level adjustments.
This research is critical as it steers the field towards more meaningful and genuine improvements in language models. RLRF’s emphasis on detailed feedback introduces a new layer of transparency to the learning process, empowering LLMs to better understand and serve their human users.
Read More: RLRF in Action
Personalized AI news from scientific papers.