LLMs
Fine-tuning
Preference data
On-policy learning
Reinforcement learning
Preference Fine-Tuning of LLMs
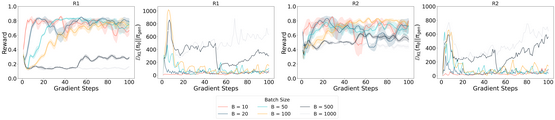
Summary:
- Critical examination of various fine-tuning methods including supervised learning, on-policy reinforcement learning, and contrastive learning for LLMs.
- It underscores the superiority of on-policy learning methods over offline models for improving fine-tuning results.
- Proposes a holistic approach by combining on-policy sampling and ‘negative gradient’ techniques.
Analysis:
- The conducted analysis sheds light on practical strategies for fine-tuning using preference data in LLM tasks.
- Highlights the need for mobilizing a diverse array of fine-tuning strategies depending on specific task requirements.
Opinion:
- This article contributes comprehensively to our understanding of how best to leverage preference data in the fine-tuning process. By advocating for a mix of various strategies, it provides actionable insights for obtaining optimal results in LLM applications.
Personalized AI news from scientific papers.