LLMs
AI Agents
Compression
Inference
Generative Models
Near-Lossless KV Cache Compression for LLM Inference
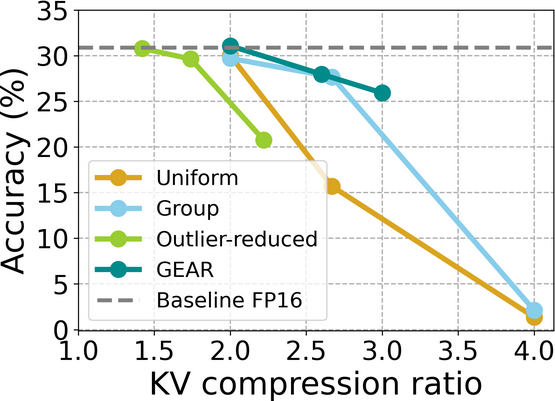
A new paper titled GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM presents a novel solution to the challenge of memory-bound LLM inference. Large language models (LLMs) rely on key-value (KV) caching to speed up the generative process, but as the demand for cache grows, efficiency becomes critical. The GEAR framework offers near-lossless compression by integrating quantization, low-rank matrices, and sparse matrices to address errors from quantization and outlier entries.
- The approach significantly improves memory footprint and system throughput.
- GEAR can achieve 4-bit KV cache compression with up to 2.38x throughput improvement.
- It reduces peak memory demands by up to 2.29x without sacrificing performance.
- Outperforms existing uniform quantization and token dropping methods.
- The authors provide public access to their code and further details here.
This research is significant as it addresses one of the critical bottlenecks in deploying LLMs—efficient memory utilization. By enabling better compression with minimal performance loss, GEAR paves the way for more scalable LLM applications. The innovation holds promise for future AI-powered systems that demand faster, resource-efficient processing of large datasets.
Personalized AI news from scientific papers.