LLM
Machine Learning
NLP
LoRA
Multi-task Learning
MixLoRA: Enhancing LLMs with LoRA for Multi-task Learning
Summary
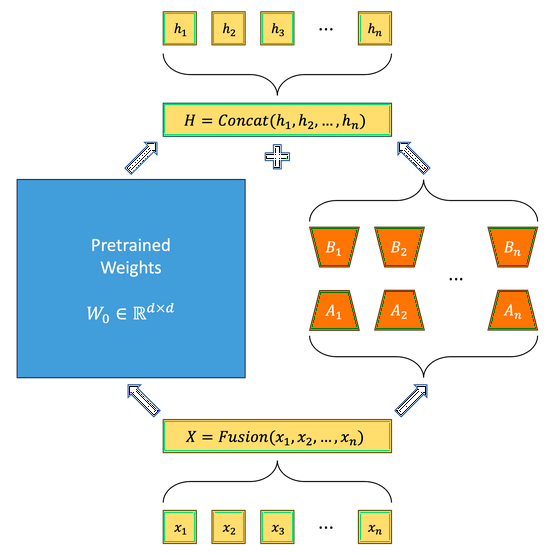
Large Language Models (LLMs) are renowned for their performance in NLP tasks, particularly when fine-tuned for specific applications. Traditional LoRA adaptations conserve GPU memory but are limited in tackling multi-task scenarios effectively. The proposed MixLoRA model integrates LoRA-based experts within a pre-trained model, enhancing its capability to handle multiple tasks simultaneously without substantial resource demands.
Key Contributions:
- Sparse MoE Model: Using LoRA-based experts allows for the creation of a resource-efficient model, reducing GPU demands by 41% and training latency by 17%.
- Independent Configuration: Each LoRA adapter can be independently configured, optimizing performance for specific tasks.
- Load Balance: Auxiliary load balance loss is introduced, ensuring load distribution across experts is even, preventing router imbalance.
Significance
MixLoRA not only mitigates resource constraints but also extends the applicability of MoE architectures to consumer-grade hardware, potentially democratizing advanced NLP capabilities. Its modular approach implies adaptability and scalability for various computational platforms.
Personalized AI news from scientific papers.