Multimodality
LLMs
Video Understanding
AI
MiniGPT4-Video: Multimodal LLMs for Video Understanding
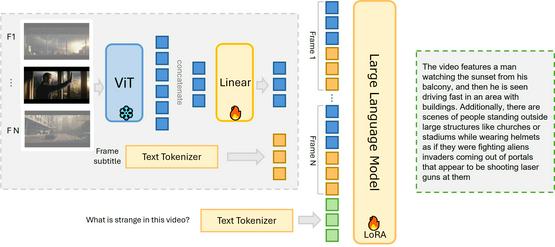
MiniGPT4-Video marks a significant leap in multimodal Large Language Models (LLMs). It is expertly built on the successful MiniGPT-v2, now extended to interpret video sequences, allowing the model to process and understand frame-by-frame multimedia content. Noteworthy advancements include:
- Interleaved visual-textual token processing
- Enhanced video query answering capabilities
- Stellar performance on benchmarks such as MSVD and TGIF
Key insights from the paper:
- Combining visual sequences with textual conversations is essential for comprehensive video understanding.
- The proposed approach substantially outperforms state-of-the-art methods, indicating its prowess in the multimodal domain.
- The accessibility of models and code promotes further research and development within the community.
Significance: MiniGPT4-Video exemplifies the evolution of AI in understanding complex multimedia content. It opens avenues for AI-driven innovations in areas like content moderation, video surveillance, and entertainment. This model’s architecture could lead to efficient designs for more robust and accurate machine learning solutions in multimodal contexts. Furthermore, with its open-source availability, it encourages collective progression in the field. Explore the full paper.
Personalized AI news from scientific papers.