High-Resolution
Vision-Language Model
LVLM
4K HD
AI Imaging
Large Vision-Language Model with High-Resolution Understanding
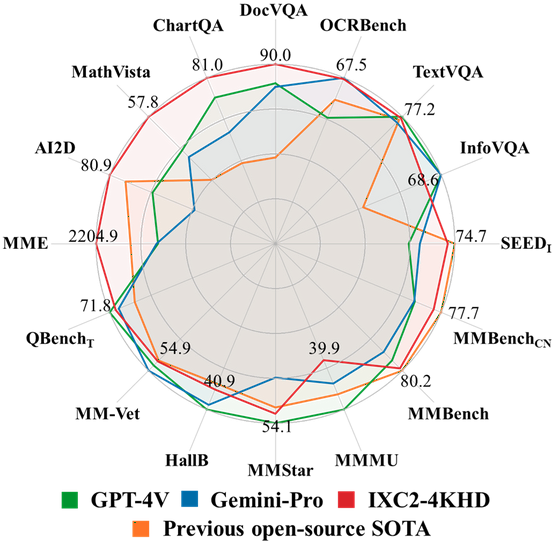
Key Findings and Methodology: InternLM-XComposer2-4KHD extends the scope of LVLM resolution capabilities, supporting a range from 336 pixels to 4K standard. The model applies a dynamic resolution technique with automatic patch configuration for better training effectiveness.
- Achieves superior scaling training resolution up to 4K HD without performance ceiling.
- Outperforms established giants like GPT-4V and Gemini Pro in certain benchmarks.
- Offers wide applicability for varying resolution requirements.
Importance and Implications: The leap in LVLMs’ resolution capabilities widens their practical application, potentially benefiting sectors such as security surveillance, medical imaging, and high-resolution content analysis. Future research may explore the efficiency of training at differing resolutions and investigate the balance between image resolution and performance metrics.
This model series serves as a testament to the possibility of integrating high-resolution understanding into LVLMs, pushing the limits of AI visual processing.
Personalized AI news from scientific papers.