LLMs
Multimodality
Reasoning
Vision-Language Models
Deductive Reasoning
Intelligent Visual Deductive Reasoning: How Close Are We?
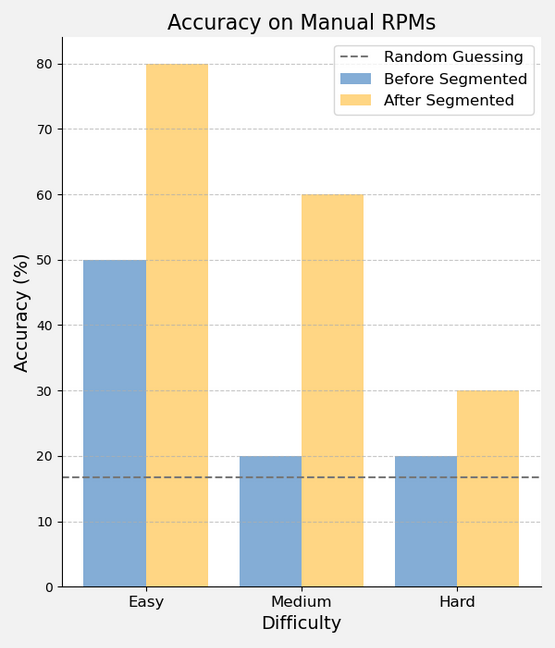
The prowess of Vision-Language Models (VLMs), including GPT-4V, is put to the test in this insightful paper titled ‘How Far Are We from Intelligent Visual Deductive Reasoning?’. While major advances on vision language tasks have been celebrated, this study probes into visual-based deductive reasoning utilizing Raven’s Progressive Matrices (RPMs) to benchmark VLMs.
- They conduct comprehensive evaluations across popular VLMs using in-context learning, self-consistency, and Chain-of-thoughts (CoT) methods on datasets like the Mensa IQ test and RAVEN.
- The findings indicate that VLMs, despite their text-based reasoning prowess, lack comparable skills in visual deductive reasoning.
- The study uncovers that strategies effective for text-based LLMs don’t translate well to visual tasks.
- VLMs struggle to decipher multiple, intricate abstract patterns in RPMs.
This paper highlights critical gaps in our journey towards AI with proficient visual reasoning, reminding us that LLMs are yet to master the art of ‘seeing’. Addressing these challenges will not only refine VLMs but also enrich AI applications requiring complex visual interpretations.
Personalized AI news from scientific papers.