Radiology
LLMs
GPT-4
Medical AI
Auto-Evaluation
Improving Radiology with Vision-based LLMs and GPT-4 Auto-Evaluation
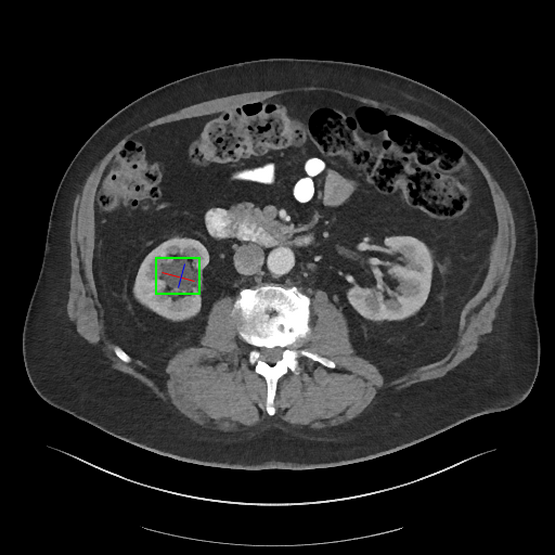
The rising demand for radiological exams propels the need for tools to alleviate the workload of radiologists. This study introduces a groundbreaking evaluation method harnessing vision-language LLMs and GPT-4 to generate and auto-evaluate summary reports for CT scans.
- The approach involves inputting CT images with abnormalities to vision-language LLMs to create detailed summaries.
- GPT-4 then deconstructs these summaries to evaluate specific aspects against ground truth with clinical relevance and factual accuracy in mind.
- A high correlation with clinicians’ evaluations emerged, indicating the efficacy of this AI-driven tactic.
- Notably, GPT-4V exhibited commendable performance, although there’s room for refinement in certain areas.
Reflecting on the study, I believe these advancements underscore the transformative potential of LLMs in medical settings. The methodology outlined offers a way forward, providing more than just descriptive accuracy and emphasizing clinical applicability that might revolutionize how medical imagery is reported and evaluated.
Personalized AI news from scientific papers.