Large Language Models
Hallucination Detection
Weakly Supervised Data
Prompt Engineering
Few-Shot Learning
Hallucination Detection in LLMs with Weakly Supervised Data
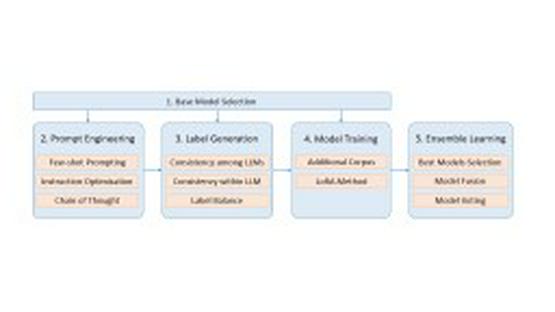
The credibility of outputs from large language models (LLMs) is critical, and detecting hallucinations — erroneous or misleading information — is an ongoing challenge. In their paper OPDAI at SemEval-2024 Task 6: Small LLMs can Accelerate Hallucination Detection with Weakly Supervised Data, Wei et al. present a system that performs remarkably in detecting hallucinations in LLMs.
- Highlights:
- Achieved second prize in hallucination detection for LLMs at SemEval-2024 Task 6.
- Uses prompt engineering and few-shot learning for validation on several LLMs.
- Selected LLMs generate high-quality weakly supervised training data for fine-tuning.
- Shows that a smaller LLM can effectively detect hallucinations, potentially aiding in the model’s reliability.
This work critically addresses the issue of trustworthiness in the results produced by LLMs and presents a method to enhance their dependability.
Personalized AI news from scientific papers.