I am interested in the hardware aspects of AI, particularly if any progress is being made to allow deploying large models onto smartphone devices
Nvidia Hopper
GPU
Tensor Cores
AI Hardware
Benchmarking
Exploring Nvidia's Hopper Architecture: A Leap Forward in GPU Technology
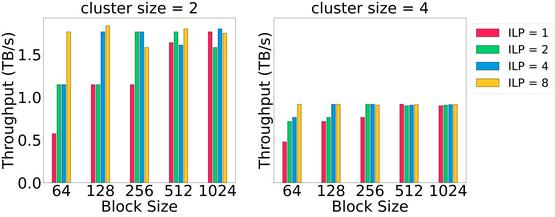
| Feature | Details |
|---|---|
| GPU Architectures Compared | Hopper, Ada, Ampere |
| New Features Examined | DPX instruction sets, distributed shared memory, FP8 tensor cores |
| Study Methodology | Extensive benchmarking of latency, throughput, and unit functionalities |
Overview of Study An extensive benchmarking study was conducted to unveil the Nvidia Hopper GPU architecture, focusing on its new tensor cores and dynamic programming features. Key aspects include latency and throughput comparisons, as well as detailed discussions on new features such as Hopper DPX, distributed shared memory, and FP8 tensor cores.
Key Findings
- Deeper insight into GPU AI functionalities and programming features.
- Thorough latency and throughput comparisons across three recent GPU architectures—Hopper, Ada, and Ampere.
- Special focus on Hopper DPX instruction sets, innovative use of distributed shared memory, and advanced tensor core technologies.
Conclusions Drawn This benchmarking reveals significant architectural improvements that aid in software optimization and offer detailed metrics for modeling GPU operations. It’s a pioneering study that aids developers and researchers in understanding and leveraging the full potential of Hopper’s architecture.
Implications for Future Research Understanding these innovations lays a groundwork for future advancements in AI-optimized computing hardware, influencing both industrial and academic pursuits. Further research could explore integration with other AI applications and scaling implications for more complex computational tasks.
Personalized AI news from scientific papers.