OpenAI Codex
High-Performance Computing
Generative AI
Programming
GitHub Copilot
Evaluation of OpenAI Codex for HPC Parallel Programming Models Kernel Generation
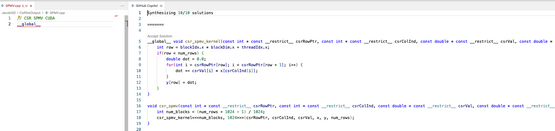
The paper presents a performance evaluation of OpenAI Codex, exploring its proficiency in generating code for various HPC (High-Performance Computing) programming models. Using GitHub Copilot capabilities, it benchmarks the generative success across multiple programming languages and models, highlighting the best practices and potential improvements.
Key Observations:
- Best performance observed in prominent models like OpenMP and CUDA.
- Diverse language support enhances the practical utility of generated code.
- Prompts specific to programming models yield more accurate responses.
Project Impact:
- Encourages broader adoption of AI-assisted code generation in HPC.
- Offers insights into improving language model training for technical domains.
- Paves the way for more efficient and accurate code generation technologies.
This research underscores the impressive adaptability of LLMs in technical spaces, potentially reshaping how coding tasks are approached. It also provides a benchmark for future models aiming to improve on the current capabilities. Further exploration into AI-driven code optimizations and their integration in real-world applications would be beneficial.
Personalized AI news from scientific papers.