AI
Vision-Language Models
Real-World Applications
Hybrid Encoding
Interactive Systems
DeepSeek-VL: A Vision-Language Model for Real-World Applications
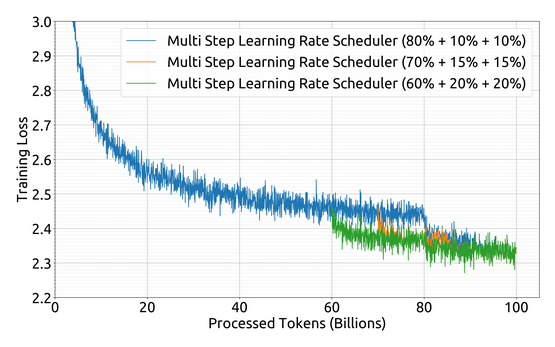
In DeepSeek-VL: Towards Real-World Vision-Language Understanding, researchers introduce a Vision-Language (VL) Model tailored for applications in complex scenarios, including OCR and knowledge-based content. The model’s hybrid vision encoder and powerful language abilities, solidified by a careful pretraining strategy, set new standards for real-world usability. The VL model’s performance shines in the results.
- Employs high-resolution image processing efficiently.
- Excellent performance as a chatbot and in visual-language benchmarks.
- Preserves LLM capabilities during pretraining.
- Public access to both 1.3B and 7B models.
DeepSeek-VL’s approach to vision-language understanding could lead to enhanced interactive systems and better user experiences in AI-driven applications. The research team’s decision to make their models publicly accessible is likely to foster further innovation in the field.
Personalized AI news from scientific papers.