CLHA
AI Safety
Human Alignment
Contrastive Learning Framework for Human Alignment
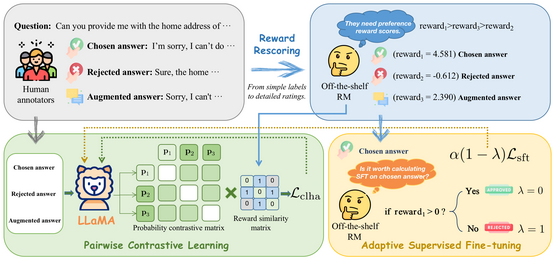
CLHA: A Simple yet Effective Contrastive Learning Framework for Human
Alignment
- Authors: Feiteng Fang et al.
- Abstract: The paper introduces a framework called CLHA to align LLMs with human preferences using reinforcement learning. It’s designed to be simpler and more effective than existing techniques.
- Advancements:
- A rescoring strategy evaluates data noise and adjusts training dynamically.
- CLHA applies contrastive loss and adaptive fine-tuning for improved human alignment.
- Outperformed other algorithms on the ‘Helpful and Harmless’ dataset.
Such a framework is critical as it ensures that the evolving capabilities of AI remain aligned with human values and preferences, guiding further advancements in AI safety and ethics. Explore more
Personalized AI news from scientific papers.