Large Language Models
Adversarial Attacks
AI Security
Model Vulnerabilities
Coercing LLMs to Do and Reveal Almost Anything
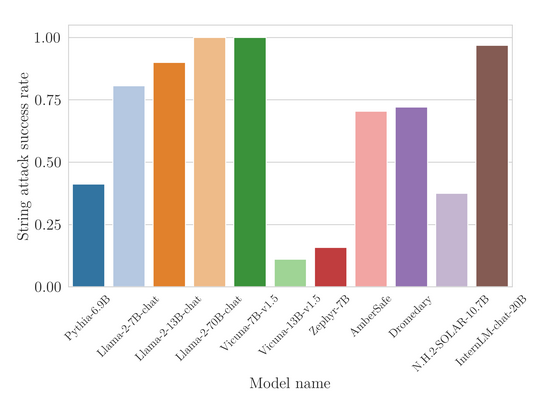
Abstract Summary: This paper presents an in-depth analysis of adversarial attacks on LLMs beyond the known ‘jailbreak’ phenomenon. The authors categorize and systematize various attack surfaces and demonstrate how these can coerce unintended behaviors in LLMs, such as misdirection and data extraction.
Key Points:
- Adversarial attacks on LLMs range in severity and intent.
- Pre-training with coding capabilities increases vulnerability to attacks.
- Certain ‘glitch’ tokens in LLM vocabularies pose security threats.
- Controlled experiments reveal the need for removing these tokens to enhance security.
Personal Opinion: The implications of this research are profound for the field of AI security. By broadening our understanding of the types of attacks that LLMs can suffer from, we can better guard these models against misuse. The study pushes for an urgent reassessment of current practices concerning both pre-training and vocabulary sanitization. It also opens up pathways for further research in developing more resilient AI systems against a broader scope of adversarial tactics.
Personalized AI news from scientific papers.