Audio Analytics
Natural Language Supervision
Contrastive Learning
Multimodal Learning
CLAP: Learning Audio Concepts from Language
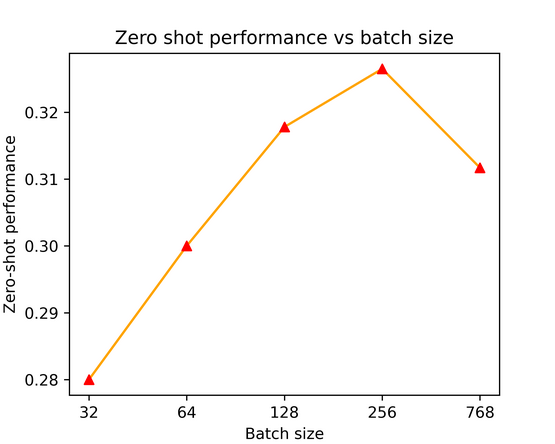
The Contrastive Language-Audio Pretraining (CLAP) project, led by Benjamin Elizalde and team, redefines how audio is understood by machines. By connecting language with sound, CLAP introduces a flexible classification system trained without restrictive labels.
- Multimodal Learning: Pairs audio with natural language to create a cohesive understanding of sounds.
- Contrastive Learning: Utilizes two encoders to map audio and text into a joint space, achieving superior Zero-Shot performance.
- Comprehensive Training: Despite fewer training pairs compared to vision models, CLAP shows impressive generality across tasks.
- Flexible Inference: Can predict a wide array of classes without additional training, showcasing the model’s adaptability.
- State-of-the-Art Achievements: Marks significant improvement in both Zero-Shot learning and supervised tasks across various domains.
CLAP illustrates a paradigm shift in audio analytics, allowing models to be adaptable and more aligned with human-like understanding of sound. Discover the strides in multimodal learning and audio concept comprehension with machines.
Personalized AI news from scientific papers.