Large Language Models
Reinforcement Learning
Direct Preference Optimization
Human Feedback
AI Safety
Advancing LLM Alignment through Mixed Preference Optimization
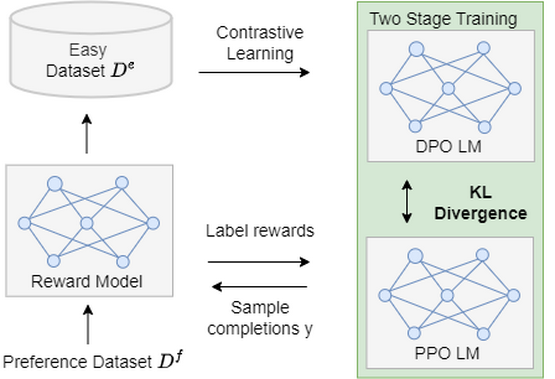
Mixed Preference Optimization (MPO) introduces a new way to align LLMs with human preferences. Authors Qi Gou and Cam-Tu Nguyen put forth a two-stage training strategy that leverages both Reinforcement Learning with Human Feedback (RLHF) and contrastive learning based methods.
- Stage 1: Initial training on an ‘easy’ dataset using Direct Preference Optimization (DPO) quickly achieves a relatively optimal policy model.
- Stage 2: Refines the LLM using RLHF on a ‘difficult’ dataset, effectively addressing potential issues with distribution shifts.
- Method Validity: MPO has been tested on public alignment datasets, showing promising results in GPT4 and human evaluations.
- Biases and Values: The technique addresses the inherited biases LLMs may contain by focusing on data alignment with human values.
- Read more about it in the full paper.
This paper lays important groundwork for creating AI systems that are not only effective but also ethically aligned. Its approach to mitigating weaknesses in existing methods can substantially contribute to developing safer and more reliable AI. Future research could expand on refining RLHF methodologies, application in other AI domains, and exploring the implications of such aligned models in real-world scenarios.
Personalized AI news from scientific papers.