Vision Transformer
GiT
Universal Language Interface
Multi-task Learning
Image Understanding
Sparse Perception
A Universal Vision Transformer
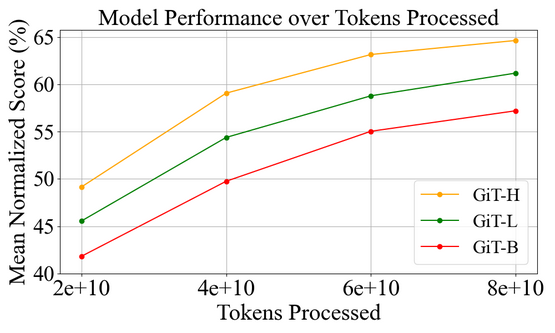
The paper ‘GiT: Towards Generalist Vision Transformer through Universal Language Interface’ proposes a visionary framework functioning across diverse visual tasks with just a basic Vision Transformer (ViT). Motivated by the versatility of the Transformer architecture in language models, the researchers present GiT — a variant adept at handling tasks ranging from captioning and detection to segmentation. This universal language interface offers a simplified architecture that’s both multi-task and capable of significant architectural unification across vision and language domains.
- Employs a universal Language interface for vision tasks
- Achieves architectural simplification between vision and language
- Illustrates the power of ViT in multi-task visual models
- Contributes to unified visual task handling without task-specific training
GiT’s innovation could streamline the application of vision Transformers across various domains, promoting a generalist approach to vision-based AI tasks. This can ultimately lead to more efficient and versatile visual AI systems capable of broader real-world applications.
Personalized AI news from scientific papers.