AI
LLMs
Multimodality
Resource Efficiency
Sustainable AI
A Survey of Resource-efficient LLM and Multimodal Foundation Models
A Survey of Resource-efficient LLM and Multimodal Foundation Models
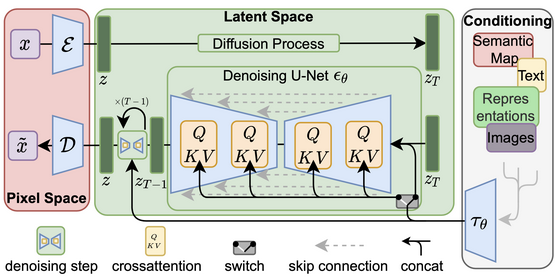
This paper provides a comprehensive analysis of the challenges and techniques related to the development of resource-efficient large foundation models, which includes large language models (LLMs), vision transformers (ViTs), diffusion models, and LLM-based multimodal models. The survey emphasizes on algorithmic and systemic aspects that aid in reducing hardware resource requirements without compromising performance.
- Highlights the ecological and economic impacts of large models
- Reviews strategies for optimizing training and deployment phases
- Analyzes cutting-edge architectures and system designs
- Discusses practical implementation and future prospects
The insights from this paper are invaluable, not just for researchers, but also for organizations aiming to implement large foundation models efficiently. The future could see further reduction in resource consumption with innovative breakthroughs inspired by this research.
Personalized AI news from scientific papers.