Self-Supervised Learning
Computer Vision
Contrastive Learning
Knowledge Distillation
Feature Learning
A Review on Discriminative Self-Supervised Learning Methods
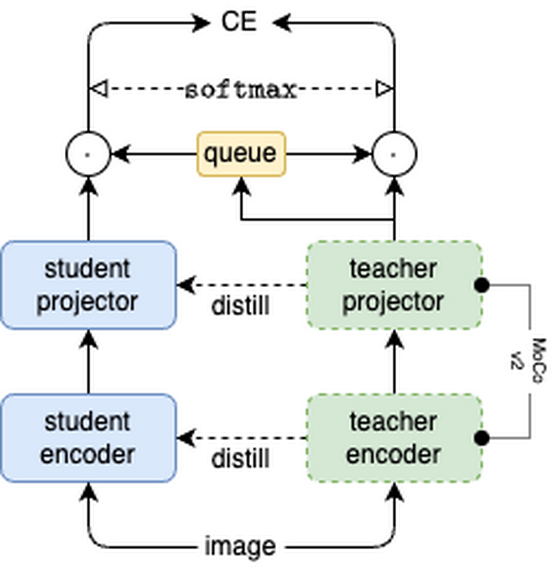
Summary\nThis comprehensive review covers the evolution and state of discriminative self-supervised learning methods in computer vision. The study discusses several techniques ranging from contrastive learning to knowledge distillation and feature decorrelation, highlighting how these approaches leverage unlabeled data to enhance learning outcomes. Key findings include:\n- Contrastive methods that utilize large datasets can significantly improve feature robustness.\n- Knowledge distillation is effective for teaching compact models the complex representations learned by larger models.\n- Novel clustering techniques contribute to better and more efficient learning processes.\n\n#### Implications\nThis paper underscores the immense potential of self-supervised learning, particularly in reducing the reliance on large annotated datasets, which can be costly and time-consuming to prepare. It also opens up new possibilities for real-world applications, such as in scenarios where data labeling is impractical.\n\n#### Further Research\nFuture studies could focus on hybrid models that integrate multiple self-supervised techniques to further enhance learning efficiency and accuracy. Additionally, the extension of these methodologies to other areas of AI, such as robotics or healthcare, could be explored.
Personalized AI news from scientific papers.