Large Language Models
LLM
Vulnerability Detection
Software Security
Reasoning Capabilities
Coding Assistants
In-Context Learning
Chain-of-Thought
Performance Evaluation
A Comprehensive Study of LLMs for Vulnerability Detection
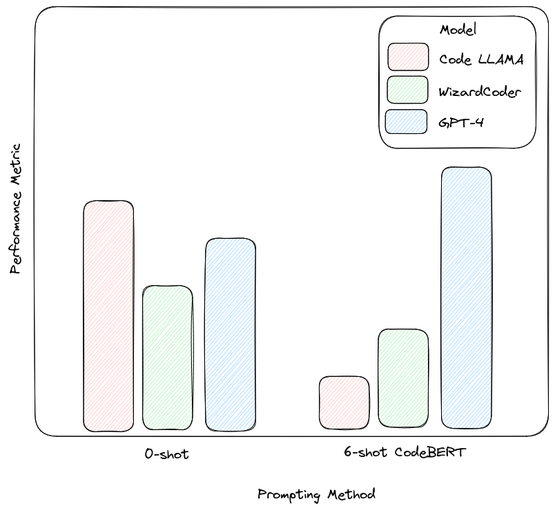
Large Language Models (LLMs) are on the frontline of assessing code security, standing as guardians against potential vulnerabilities. In a recent study, researchers scrutinize the capability of eleven state-of-the-art LLMs customarily employed as coding assistants. Their quest? To push the envelope on what these models can discern regarding software vulnerabilities using enhanced prompting practices rooted in in-context learning and a chain-of-thought approach, along with the addition of three novel prompting techniques.
Here’s a distilled summary of their findings:
- LLMs still fumble with vulnerability detection, with Balanced Accuracy lingering between 0.5-0.63.
- Buggy versus fixed code: LLMs couldn’t tell them apart 76% of the time.
- Out of 287 LLM responses analyzed, a whopping 57% were erroneous.
- Mapping the bug’s location and identity proved elusive; 6 out of 27 bugs in DbgBench were localized correctly, and yet, humans aced this task with a success rate of 70-100%.
While LLMs demonstrate prowess in sundry tasks, they flounder in comprehending complex code structures critical to security.
Discover more about this intriguing examination, including access to the authors’ data and code, here.
I believe this study is pivotal, showcasing both the impressive reach and the clear limitations of LLMs in the niche of vulnerability detection. It calls for further specialized advancements before LLMs can truly become reliable sentinels in software security.
Personalized AI news from scientific papers.