Stay updated daily with trending AI research
7 days free trialPick your own topicsAutomated AI summaries
LLM Pruning and Distillation in Practice: The Minitron Approach
Abstract
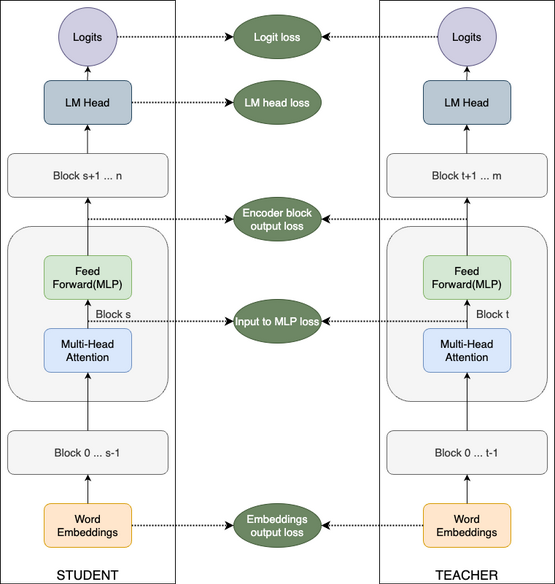
We present a comprehensive report on compressing the Llama 3.1 8B and Mistral NeMo 12B models to 4B and 8B parameters, respectively, using pruning and distillation. We explore two distinct pruning strategies: (1) depth pruning and (2) joint hidden/attention/MLP (width) pruning, and evaluate the results on common benchmarks from the LM Evaluation Harness. The models are then aligned with NeMo Aligner and tested in instruct-tuned versions. This approach produces a compelling 4B model from Llama 3.1 8B and a state-of-the-art Mistral-NeMo-Minitron-8B (MN-Minitron-8B for brevity) model from Mistral NeMo 12B. We found that with no access to the original data, it is beneficial to slightly fine-tune teacher models on the distillation dataset. We open-source our base model weights on Hugging Face with a permissive license.
© 2025 Adaptive Plus Inc.1216 Broadway, Suite 213,575 Market Str, San Francisco, CA