Stay updated daily with trending AI research
7 days free trialPick your own topicsAutomated AI summaries
SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models
Abstract
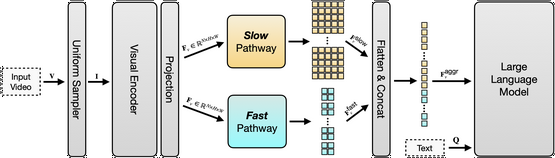
We propose SlowFast-LLaVA (or SF-LLaVA for short), a training-free video large language model (LLM) that can jointly capture the detailed spatial semantics and long-range temporal context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features at a low frame rate while keeping as many spatial details as possible (e.g., with 24x24 tokens), and the Fast pathway operates on a high frame rate but uses a larger spatial pooling stride (e.g., downsampling 6x) to focus on the motion cues. As a result, this design allows us to adequately capture both spatial and temporal features that are beneficial for understanding details along the video. Experimental results show that SF-LLaVA outperforms existing training-free methods on a wide range of video tasks. On some benchmarks, it achieves comparable or even better performance compared to state-of-the-art Video LLMs that are fine-tuned on video datasets.
© 2025 Adaptive Plus Inc.1216 Broadway, Suite 213,575 Market Str, San Francisco, CA