Stay updated daily with trending AI research
7 days free trialPick your own topicsAutomated AI summaries
Stable Audio Open
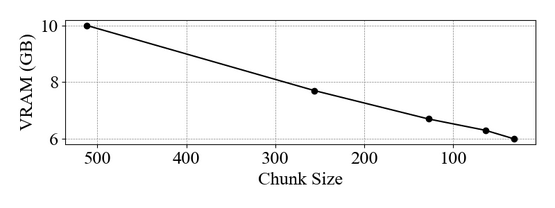
Abstract
Open generative models are vitally important for the community, allowing for fine-tunes and serving as baselines when presenting new models. However, most current text-to-audio models are private and not accessible for artists and researchers to build upon. Here we describe the architecture and training process of a new open-weights text-to-audio model trained with Creative Commons data. Our evaluation shows that the model's performance is competitive with the state-of-the-art across various metrics. Notably, the reported FDopenl3 results (measuring the realism of the generations) showcase its potential for high-quality stereo sound synthesis at 44.1kHz.
© 2025 Adaptive Plus Inc.1216 Broadway, Suite 213,575 Market Str, San Francisco, CA